Imaginative and prescient-language fashions (VLMs) play a vital function in multimodal duties like picture retrieval, captioning, and medical diagnostics by aligning visible and linguistic information. Nonetheless, understanding negation in these fashions stays one of many most important challenges. Negation is crucial for nuanced purposes, comparable to distinguishing “a room with out home windows” from “a room with home windows.” Regardless of their developments, present VLMs fail to interpret negation reliably, severely limiting their effectiveness in high-stakes domains like security monitoring and healthcare. Addressing this problem is important to develop their applicability in real-world situations.
The present VLMs, comparable to CLIP, use shared embedding areas to align visible and textual representations. Although these fashions excel in duties comparable to cross-modal retrieval and picture captioning, their efficiency falls sharply when coping with negated statements. This limitation arises attributable to pretraining information biases as a result of the coaching datasets include primarily affirmative examples, resulting in affirmation bias, the place fashions deal with negated and affirmative statements as equivalents. Present benchmarks comparable to CREPE and CC-Neg depend on simplistic templated examples that don’t signify the richness and depth of negation in pure language. VLMs are likely to collapse the embeddings of negated and affirmative captions so this can be very difficult to tease aside fine-grained variations between the ideas. This poses an issue in utilizing VLMs for exact language understanding purposes, for example, querying a medical imaging database with complicated inclusion and exclusion standards.
To deal with these limitations, researchers from MIT, Google DeepMind, and the College of Oxford proposed the NegBench framework for the analysis and enchancment of negation comprehension over VLMs. The framework assesses two elementary duties: Retrieval with Negation (Retrieval-Neg), which examines the mannequin’s capability to retrieve photos in accordance with each affirmative and negated specs, comparable to “a seaside with out individuals,” and A number of Alternative Questions with Negation (MCQ-Neg), which evaluates nuanced comprehension by necessitating that fashions choose applicable captions from slight variations. It makes use of monumental artificial datasets, like CC12M-NegCap and CC12M-NegMCQ, augmented with thousands and thousands of captions that include a variety of negation situations. This may expose VLMs to considerably difficult negatives and paraphrased captions, enhancing the coaching and analysis of fashions. Normal datasets, comparable to COCO and MSR-VTT, have been additionally tailored, together with negated captions and paraphrases, to additional develop linguistic range and take a look at the robustness. By incorporating different and sophisticated negation examples, NegBench successfully overcomes current limitations, considerably enhancing mannequin efficiency and generalization.
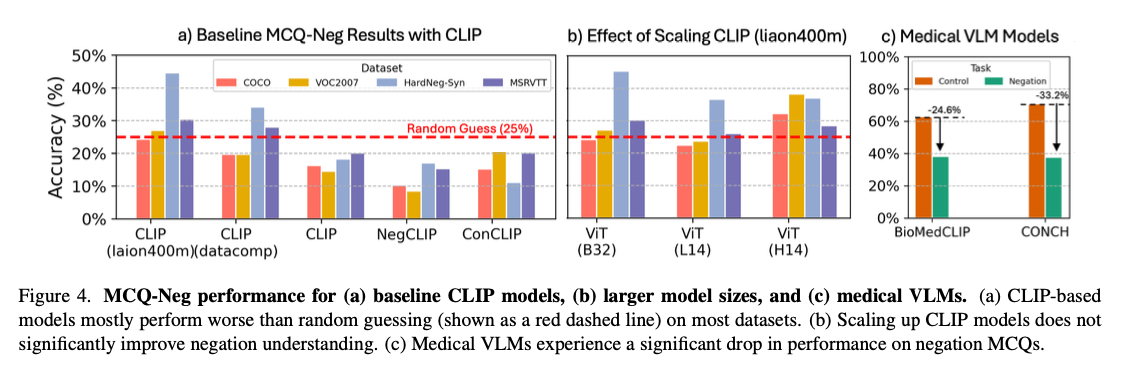
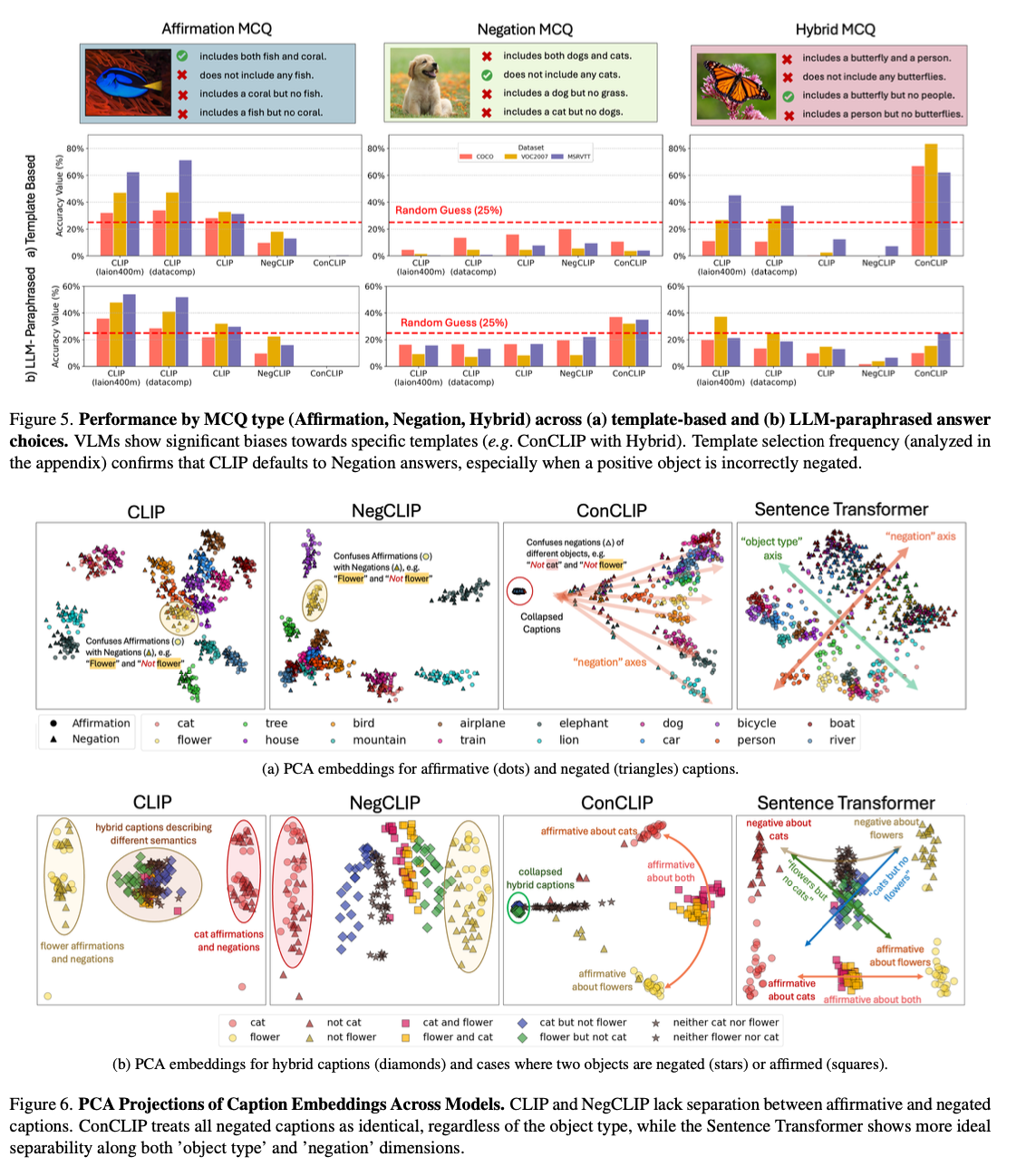
NegBench leverages each actual and artificial datasets to check negation comprehension. Datasets like COCO, VOC2007, and CheXpert have been tailored to incorporate negation situations, comparable to “This picture consists of bushes however not buildings.” For MCQs, templates like “This picture consists of A however not B” have been used alongside paraphrased variations for range. NegBench is additional augmented with the HardNeg-Syn dataset, the place photos are synthesized to current pairs differing from one another primarily based on the prevalence or absence of sure objects solely, therefore constituting tough circumstances for negation understanding. Mannequin fine-tuning relied on two coaching aims. On one hand, contrastive loss facilitated the alignment between image-caption pairs, enhancing efficiency in retrieval. Then again, utilizing multiple-choice loss helped in making fine-grained negation judgments by preferring the proper captions within the MCQ context.

The fine-tuned fashions confirmed appreciable enhancements in retrieval and comprehension duties utilizing the negation-enriched datasets. For retrieval, the mannequin’s recall will increase by 10% for negated queries, the place efficiency is sort of at par with commonplace retrieval duties. Within the multiple-choice query duties, accuracy enhancements of as much as 40% have been reported, displaying a greater means to distinguish between the refined affirmative and negated captions. Developments have been uniform over a variety of datasets, together with COCO and MSR-VTT, and on artificial datasets like HardNeg-Syn, the place fashions dealt with negation and sophisticated linguistic developments appropriately. This implies that representing situations with various sorts of negation in coaching and testing is efficient in lowering affirmation bias and generalization.
NegBench addresses a crucial hole in VLMs by being the primary work to deal with their incapacity to grasp negation. It brings important enhancements in retrieval and comprehension duties by incorporating various negation examples into trAIning and analysis. Such enhancements open up avenues for way more sturdy AI methods which can be able to nuanced language understanding, with essential implications for crucial domains like medical diagnostics and semantic content material retrieval.
Take a look at the Paper and Code. All credit score for this analysis goes to the researchers of this mission. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 65k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s captivated with information science and machine studying, bringing a robust tutorial background and hands-on expertise in fixing real-life cross-domain challenges.