Giant language mannequin (LLM) post-training focuses on refining mannequin habits and enhancing capabilities past their preliminary coaching part. It contains supervised fine-tuning (SFT) and reinforcement studying to align fashions with human preferences and particular process necessities. Artificial knowledge is essential, permitting researchers to guage and optimize post-training methods. Nevertheless, open analysis on this area continues to be in its early levels, going through knowledge availability and scalability limitations. With out high-quality datasets, analyzing the efficiency of various fine-tuning methods and assessing their effectiveness in real-world functions turns into troublesome.
One of many main challenges on this area is the shortage of large-scale, publicly out there artificial datasets appropriate for LLM post-training. Researchers should entry various conversational datasets to conduct significant comparative analyses and enhance alignment methods. The shortage of standardized datasets limits the power to guage post-training efficiency throughout totally different fashions. Furthermore, large-scale knowledge era prices and computational necessities are prohibitive for a lot of tutorial establishments. These components create obstacles to bettering mannequin effectivity and making certain fine-tuned LLMs generalize effectively throughout duties and consumer interactions.
Present approaches to artificial knowledge assortment for LLM coaching depend on a mix of model-generated responses and benchmark datasets. Datasets, comparable to WildChat-1M from Allen AI and LMSys-Chat-1M, present useful insights into artificial knowledge utilization. Nevertheless, they’re typically restricted in scale and mannequin range. Researchers have developed numerous methods to evaluate artificial knowledge high quality, together with LLM judge-based evaluations and effectivity metrics for runtime and VRAM utilization. Regardless of these efforts, the sector nonetheless lacks a complete and publicly accessible dataset that permits for large-scale experimentation and optimization of post-training methodologies.
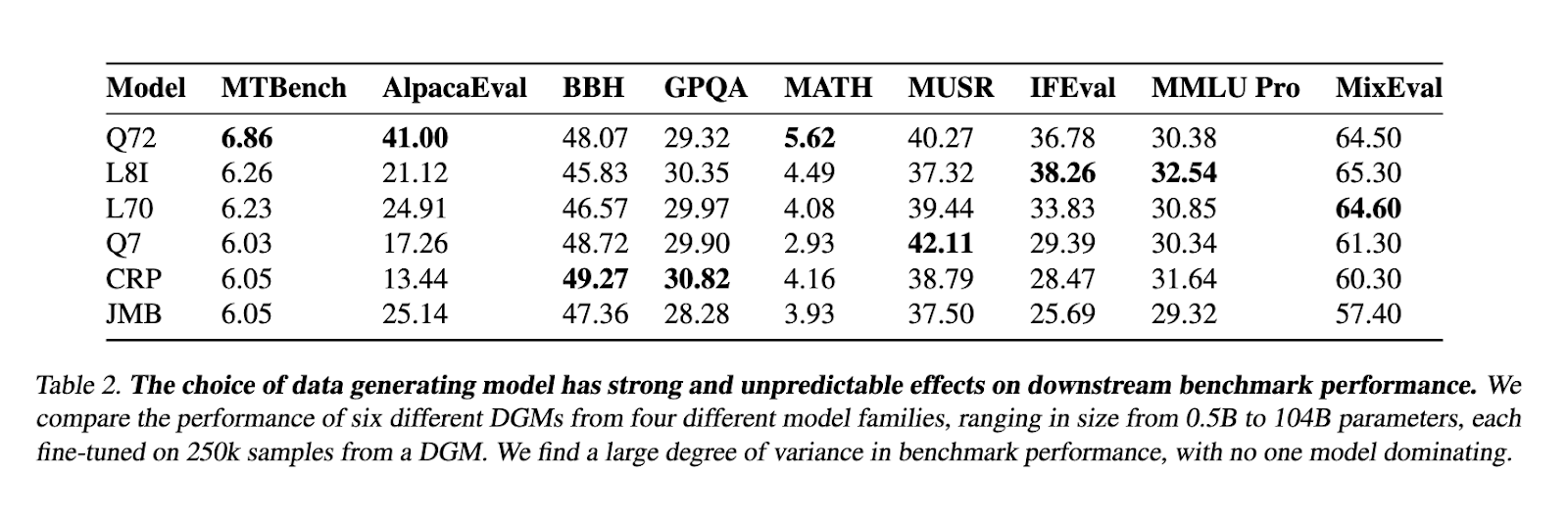
Researchers from New York College (NYU) launched WILDCHAT-50M, an intensive dataset designed to facilitate LLM post-training. The dataset builds upon the WildChat assortment and expands it to incorporate responses from over 50 open-weight fashions. These fashions vary from 0.5 billion to 104 billion parameters, making WILDCHAT-50M the most important and most various public dataset of chat transcripts. The dataset allows a broad comparative evaluation of artificial knowledge era fashions and is a basis for additional bettering post-training methods. By making WILDCHAT-50M publicly accessible, the analysis crew goals to bridge the hole between industry-scale post-training and tutorial analysis.
The dataset was developed by synthesizing chat transcripts from a number of fashions, every collaborating in over a million multi-turn conversations. The dataset contains roughly 125 million chat transcripts, providing an unprecedented scale of artificial interactions. The information assortment course of befell over two months utilizing a shared analysis cluster of 12×8 H100 GPUs. This setup allowed researchers to optimize runtime effectivity and guarantee a various vary of responses. The dataset additionally served as the idea for RE-WILD, a novel supervised fine-tuning (SFT) combine that enhances LLM coaching effectivity. By this method, researchers efficiently demonstrated that WILDCHAT-50M might optimize knowledge utilization whereas sustaining excessive ranges of post-training efficiency.
The effectiveness of WILDCHAT-50M was validated by means of a collection of rigorous benchmarks. The RE-WILD SFT method, primarily based on WILDCHAT-50M, outperformed the Tulu-3 SFT combination developed by Allen AI whereas utilizing solely 40% of the dataset measurement. The analysis included a number of efficiency metrics, with particular enhancements in response coherence, mannequin alignment, and benchmark accuracy. The dataset’s potential to reinforce runtime effectivity was additionally highlighted, with throughput effectivity analyses indicating substantial enhancements in token processing pace. Additional, fashions fine-tuned utilizing WILDCHAT-50M demonstrated important enhancements in instruction-following capabilities and total chat efficiency throughout numerous analysis benchmarks.
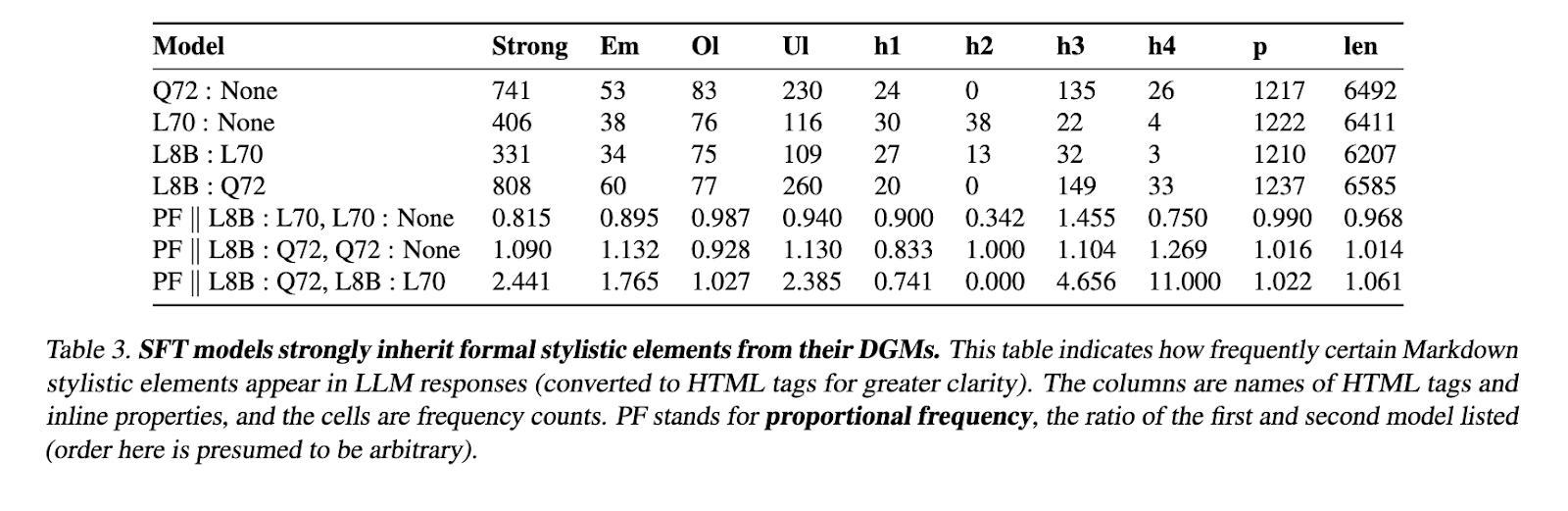
This analysis underscores the significance of high-quality artificial knowledge in LLM post-training and presents WILDCHAT-50M as a useful useful resource for optimizing mannequin alignment. By offering a large-scale, publicly out there dataset, the researchers have enabled additional developments in supervised fine-tuning methodologies. The comparative analyses carried out on this examine supply key insights into the effectiveness of various knowledge era fashions and post-training methods. Shifting ahead, the introduction of WILDCHAT-50M is anticipated to help a broader vary of educational and industrial analysis efforts, finally contributing to growing extra environment friendly and adaptable language fashions.
Take a look at the Paper, Dataset on Hugging Face and GitHub Web page. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be part of our Telegram Channel and LinkedIn Group. Don’t Neglect to affix our 75k+ ML SubReddit.
Nikhil is an intern advisor at Marktechpost. He’s pursuing an built-in twin diploma in Supplies on the Indian Institute of Expertise, Kharagpur. Nikhil is an AI/ML fanatic who’s at all times researching functions in fields like biomaterials and biomedical science. With a robust background in Materials Science, he’s exploring new developments and creating alternatives to contribute.
 Reminiscence Footprint")