Open-vocabulary object detection (OVD) goals to detect arbitrary objects with user-provided textual content labels. Though current progress has enhanced zero-shot detection capability, present strategies handicap themselves with three necessary challenges. They closely depend upon costly and large-scale region-level annotations, that are exhausting to scale. Their captions are usually brief and never contextually wealthy, which makes them insufficient in describing relationships between objects. These fashions additionally lack robust generalization to new object classes, primarily aiming to align particular person object options with textual labels as an alternative of utilizing holistic scene understanding. Overcoming these limitations is important to pushing the sphere additional and creating simpler and versatile vision-language fashions.
Earlier strategies have tried to reinforce OVD efficiency by making use of vision-language pretraining. Fashions reminiscent of GLIP, GLIPv2, and DetCLIPv3 mix contrastive studying and dense captioning approaches to advertise object-text alignment. Nevertheless, these strategies nonetheless have necessary points. Area-based captions solely describe a single object with out contemplating the complete scene, which confines contextual understanding. Coaching includes huge labeled datasets, so scalability is a crucial concern. And not using a approach to perceive complete image-level semantics, these fashions are incapable of detecting new objects effectively.
Researchers from Solar Yat-sen College, Alibaba Group, Peng Cheng Laboratory, Guangdong Province Key Laboratory of Info Safety Know-how, and Pazhou Laboratory suggest LLMDet, a novel open-vocabulary detector educated underneath the supervision of a massive language mannequin. This framework introduces a brand new dataset, GroundingCap-1M, which consists of 1.12 million pictures, every annotated with detailed image-level captions and brief region-level descriptions. The mixing of each detailed and concise textual info strengthens vision-language alignment, offering richer supervision for object detection. To boost studying effectivity, the coaching technique employs twin supervision, combining a grounding loss that aligns textual content labels with detected objects and a caption era loss that facilitates complete picture descriptions alongside object-level captions. A big language mannequin is integrated to generate lengthy captions describing whole scenes and brief phrases for particular person objects, bettering detection accuracy, generalization, and rare-class recognition. Moreover, this strategy contributes to multi-modal studying by reinforcing the interplay between object detection and large-scale vision-language fashions.
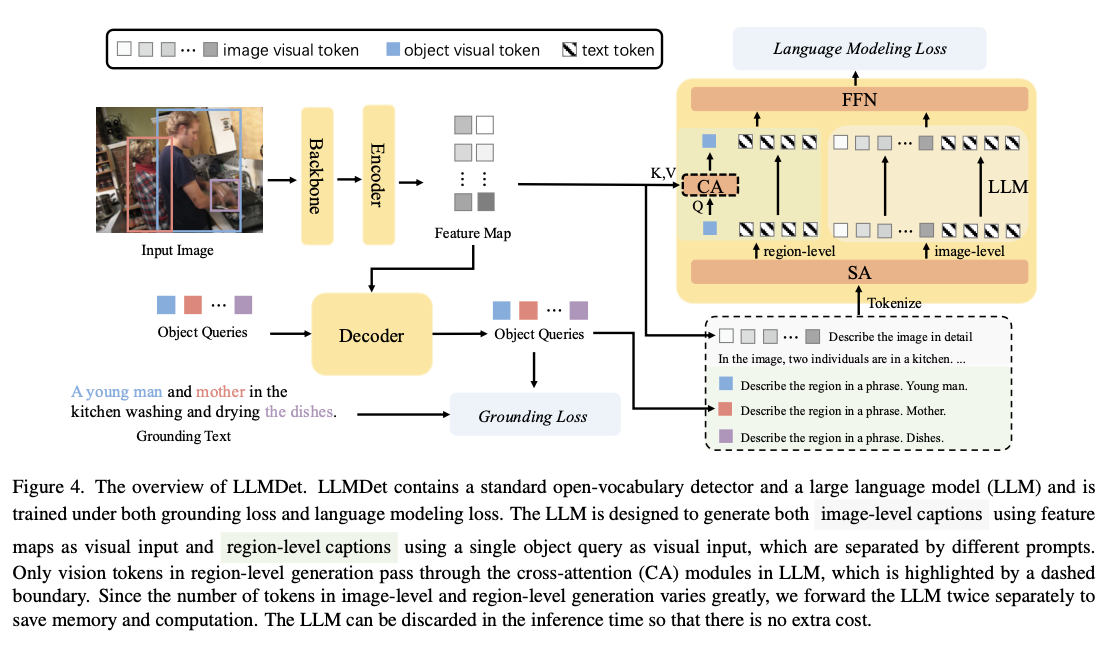
The coaching pipeline consists of two main levels. First, a projector is optimized to align the item detector’s visible options with the characteristic house of the massive language mannequin. Within the subsequent stage, the detector undergoes joint fine-tuning with the language mannequin utilizing a mixture of grounding and captioning losses. The dataset used for this coaching course of is compiled from COCO, V3Det, GoldG, and LCS, making certain that every picture is annotated with each brief region-level descriptions and intensive lengthy captions. The structure is constructed on the Swin Transformer spine, using MM-GDINO as the item detector whereas integrating captioning capabilities via massive language fashions. The mannequin processes info at two ranges: region-level descriptions categorize objects, whereas image-level captions seize scene-wide contextual relationships. Regardless of incorporating a complicated language mannequin throughout coaching, computational effectivity is maintained because the language mannequin is discarded throughout inference.
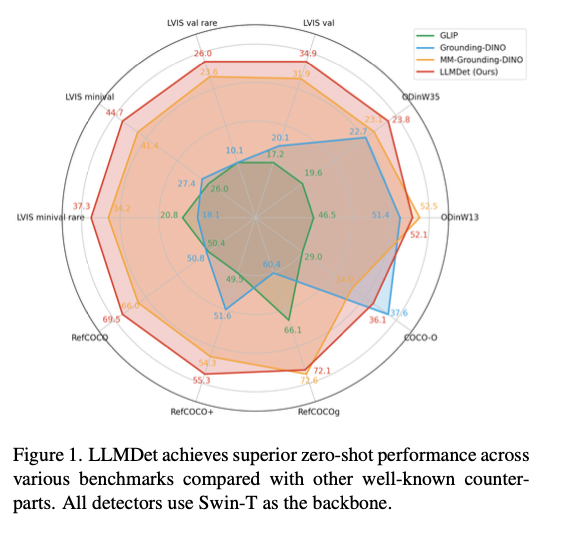
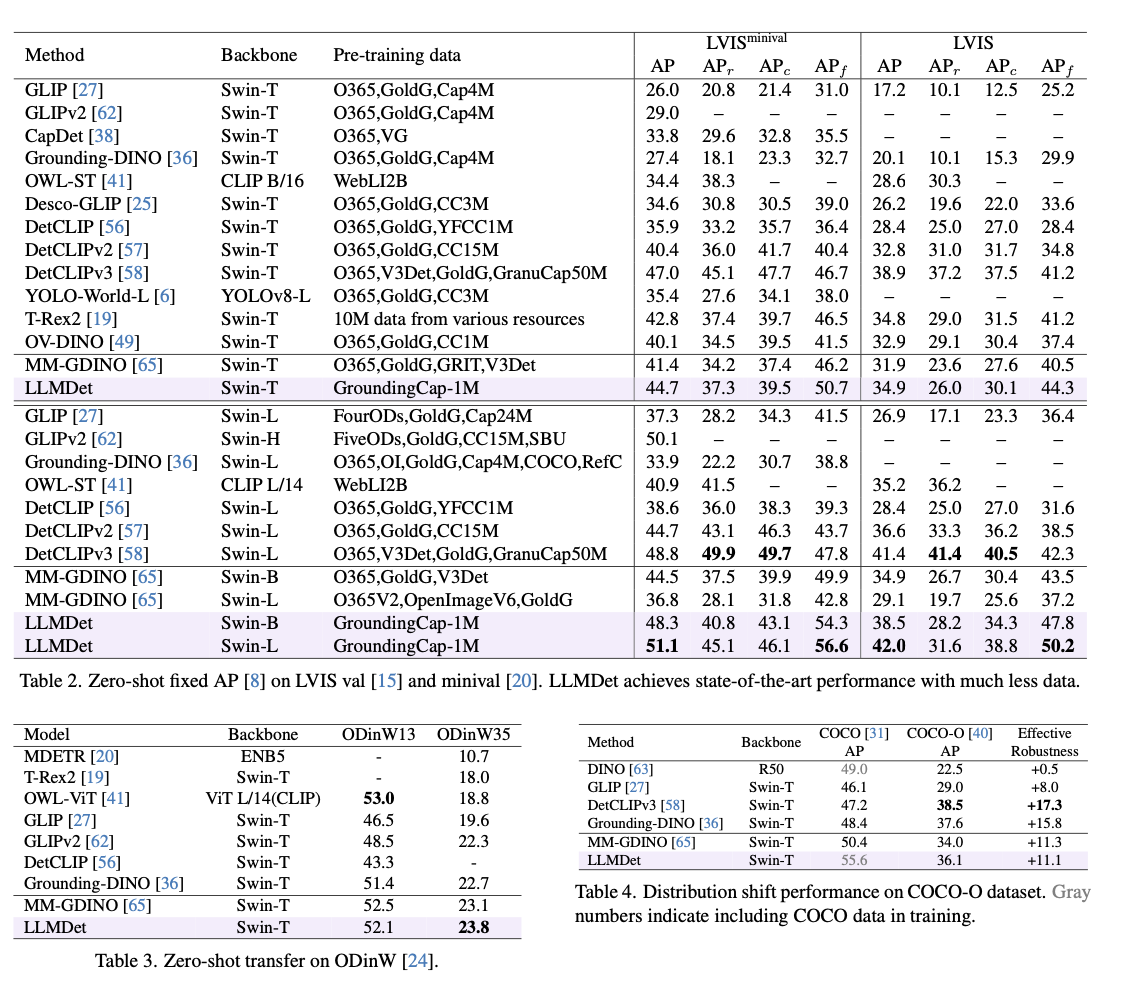
This strategy attains state-of-the-art efficiency over a variety of open-vocabulary object detection benchmarks, with significantly improved detection accuracy, generalization, and robustness. It surpasses prior fashions by 3.3%–14.3% AP on LVIS, with clear enchancment within the identification of uncommon lessons. On ODinW, a benchmark for object detection over a variety of domains, it exhibits higher zero-shot transferability. Robustness to area transition can be confirmed via its improved efficiency on COCO-O, a dataset measuring efficiency underneath pure variations. In referential expression comprehension duties, it attains the perfect accuracy on RefCOCO, RefCOCO+, and RefCOCOg, affirming its capability for textual description alignment with object detection. Ablation experiments present that image-level captioning and region-level grounding together make vital contributions to efficiency, particularly in object detection for uncommon objects. As nicely, incorporating the realized detector into multi-modal fashions improves vision-language alignment, suppresses hallucinations, and advances accuracy in visible question-answering.
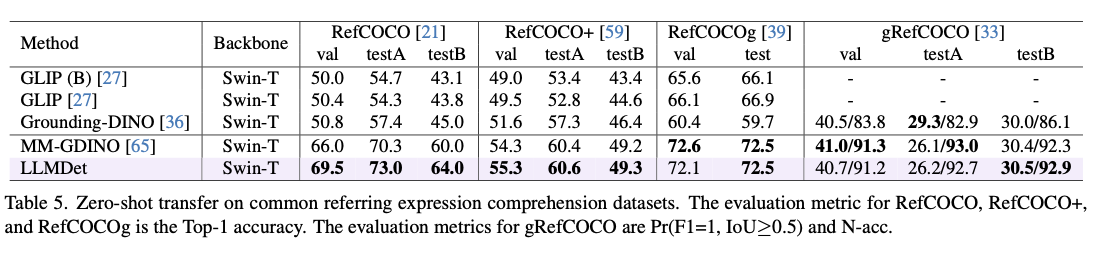
Through the use of massive language fashions in open-vocabulary detection, LLMDet gives a scalable and environment friendly studying paradigm. This growth treatments the first challenges to current OVD frameworks, with state-of-the-art efficiency on a number of detection benchmarks and improved zero-shot generalization and rare-class detection. Imaginative and prescient-language studying integration promotes cross-domain adaptability and enhances multi-modal interactions, displaying the promise of language-guided supervision in object detection analysis.
Take a look at the Paper. All credit score for this analysis goes to the researchers of this undertaking. Additionally, don’t neglect to observe us on Twitter and be a part of our Telegram Channel and LinkedIn Group. Don’t Neglect to hitch our 75k+ ML SubReddit.
Aswin AK is a consulting intern at MarkTechPost. He’s pursuing his Twin Diploma on the Indian Institute of Know-how, Kharagpur. He’s keen about information science and machine studying, bringing a powerful tutorial background and hands-on expertise in fixing real-life cross-domain challenges.