Quantization is a vital method in deep studying for lowering computational prices and bettering mannequin effectivity. Massive-scale language fashions demand important processing energy, which makes quantization important for minimizing reminiscence utilization and enhancing inference pace. By changing high-precision weights to lower-bit codecs resembling int8, int4, or int2, quantization reduces storage necessities. Nonetheless, normal methods usually degrade accuracy, particularly at low precisions like int2. Researchers should compromise accuracy for effectivity or keep a number of fashions with completely different quantization ranges. New methods are strongly wanted to protect mannequin high quality whereas optimizing computational effectivity.
The elemental drawback with quantization is dealing with precision discount precisely. The approaches accessible to this point both practice distinctive fashions per precision or don’t make the most of the integer information kind’s hierarchical nature. Accuracy loss in quantization, as within the case of Int2, is most tough as a result of its reminiscence positive aspects hamper widespread utilization. LLMs like Gemma-2 9B and Mistral 7B are very computationally intensive, and a way that permits a single mannequin to function on a number of precision ranges would considerably enhance effectivity. The need for a high-performance, versatile quantization methodology has prompted researchers to hunt options outdoors of standard strategies.
A number of quantization methods exist, every balancing accuracy and effectivity. Studying-free strategies like MinMax and GPTQ use statistical scaling to map mannequin weights to decrease bit widths with out modifying parameters, however they lose accuracy at low precisions. Studying-based strategies like Quantization Conscious Coaching (QAT) and OmniQuant optimize quantization parameters utilizing gradient descent. QAT updates mannequin parameters to cut back post-quantization accuracy loss, whereas OmniQuant learns to scale and shift parameters with out modifying core weights. Nonetheless, each strategies nonetheless require separate fashions for various precisions, complicating deployment.
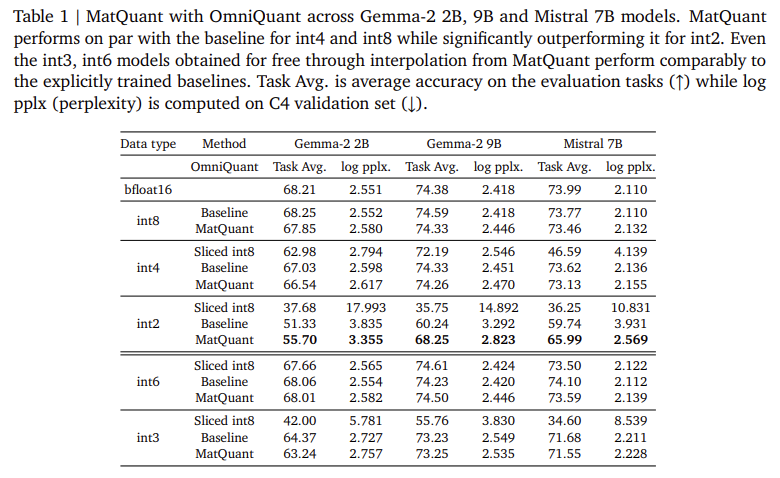
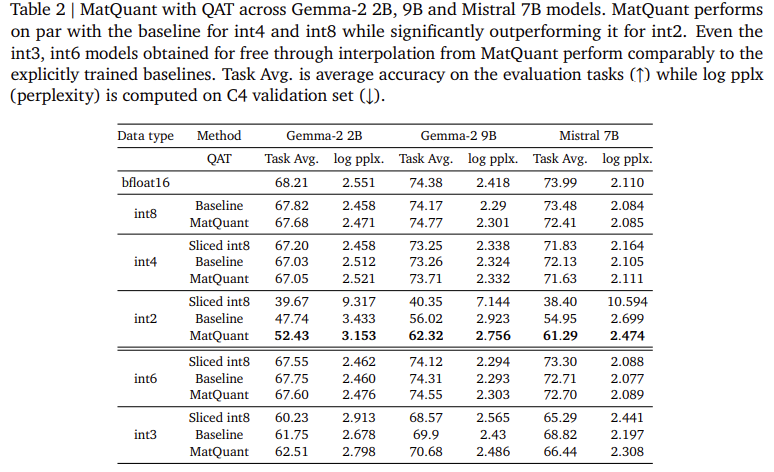
Researchers at Google DeepMind launched Matryoshka Quantization (MatQuant) to create a single mannequin that capabilities throughout a number of precision ranges. Not like standard strategies that deal with every bit-width individually, MatQuant optimizes a mannequin for int8, int4, and int2 utilizing a shared bit illustration. This permits fashions to be deployed at completely different precisions with out retraining, lowering computational and storage prices. MatQuant extracts lower-bit fashions from a high-bit mannequin whereas preserving accuracy by leveraging the hierarchical construction of integer information sorts. Testing on Gemma-2 2B, Gemma-2 9B, and Mistral 7B fashions confirmed that MatQuant improves int2 accuracy by as much as 10% over normal quantization methods like QAT and OmniQuant.
MatQuant represents mannequin weights at completely different precision ranges utilizing shared most important bits (MSBs) and optimizes them collectively to keep up accuracy. The coaching course of incorporates co-training and co-distillation, making certain that the int2 illustration retains vital info sometimes misplaced in standard quantization. As a substitute of discarding lower-bit constructions, MatQuant integrates them right into a multi-scale optimization framework for environment friendly compression with out efficiency loss.
Experimental evaluations of MatQuant exhibit its skill to mitigate accuracy loss from quantization. Researchers examined the tactic on Transformer-based LLMs, specializing in quantizing Feed-Ahead Community (FFN) parameters, a key think about inference latency. Outcomes present that MatQuant’s int8 and int4 fashions obtain comparable accuracy to independently skilled baselines whereas outperforming them at int2 precision. On the Gemma-2 9B mannequin, MatQuant improved int2 accuracy by 8.01%, whereas the Mistral 7B mannequin noticed a 6.35% enchancment over conventional quantization strategies. The examine additionally discovered that MatQuant’s right-shifted quantized weight distribution enhances accuracy throughout all bit-widths, significantly benefiting lower-precision fashions. Additionally, MatQuant permits seamless bit-width interpolation and layer-wise Combine’n’Match configurations, permitting versatile deployment based mostly on {hardware} constraints.
A number of Key Takeaways emerge from the Analysis on MatQuant:
- Multi-Scale Quantization: MatQuant introduces a novel method to quantization by coaching a single mannequin that may function at a number of precision ranges (e.g., int8, int4, int2).
- Nested Bit Construction Exploitation: The method leverages the inherent nested construction inside integer information sorts, permitting smaller bit-width integers to be derived from bigger ones.
- Enhanced Low-Precision Accuracy: MatQuant considerably improves the accuracy of int2 quantized fashions, outperforming conventional quantization strategies like QAT and OmniQuant by as much as 8%.
- Versatile Software: MatQuant is suitable with present learning-based quantization methods resembling Quantization Conscious Coaching (QAT) and OmniQuant.
- Demonstrated Efficiency: The tactic was efficiently utilized to quantize the FFN parameters of LLMs like Gemma-2 2B, 9B, and Mistral 7B, showcasing its sensible utility.
- Effectivity Beneficial properties: MatQuant permits the creation of fashions that supply a greater trade-off between accuracy and computational price, making it perfect for resource-constrained environments.
- Pareto-Optimum Commerce-Offs: It permits for seamless extraction of interpolative bit-widths, resembling int6 and int3, and admits a dense accuracy-vs-cost Pareto-optimal trade-off by enabling layer-wise Combine’n’Match of various precisions.
In conclusion, MatQuant presents an answer to managing a number of quantized fashions by using a multi-scale coaching method that exploits the nested construction of integer information sorts. This gives a versatile, high-performance choice for low-bit quantization in environment friendly LLM inference. This analysis demonstrates {that a} single mannequin might be skilled to function at a number of precision ranges with out considerably declining accuracy, significantly at very low bit widths, marking an necessary development in mannequin quantization methods.
Try the Paper. All credit score for this analysis goes to the researchers of this venture. Additionally, be at liberty to comply with us on Twitter and don’t overlook to hitch our 75k+ ML SubReddit.
Asif Razzaq is the CEO of Marktechpost Media Inc.. As a visionary entrepreneur and engineer, Asif is dedicated to harnessing the potential of Synthetic Intelligence for social good. His most up-to-date endeavor is the launch of an Synthetic Intelligence Media Platform, Marktechpost, which stands out for its in-depth protection of machine studying and deep studying information that’s each technically sound and simply comprehensible by a large viewers. The platform boasts of over 2 million month-to-month views, illustrating its reputation amongst audiences.